|
|
 |
|
HaGenLex (HAgen GErmaN LEXicon) ist ein domänenunabhängiges Computerlexikon für das Deutsche, das seit 1996 am Lehrgebiet für Intelligente Informations- und Kommunikationssysteme (IICS) der FernUniversität in Hagen entwickelt wurde. HaGenLex-Einträge sind mit detaillierter morphosyntaktischer und semantischer Information versehen. Das Kernlexikon von HaGenLex umfasst gegenwärtig (07/2005):
| 12986 | Substantiv-Einträge |
| 6911 | Verb-Einträge |
| 3278 | Adjektiv-Einträge |
| 579 | Adverb-Einträge |
Der lexikalische Bestand von HaGenLex wurde vorwiegend manuell auf der Grundlage von Frequenzlisten und Wörterbüchern erstellt. Eine ausführliche Darstellung von HaGenLex gibt [1].
Die semantische Darstellung in HaGenLex basiert auf dem MultiNet Paradigma, dessen Darstellungsmittel eine Hierarchie von 45 ontologischen Sorten (object, action, location, property, etc) und mehr als 100 semantische Relationen und Funktionen umfassen. Außerdem werden die in Abbildung 1 aufgelisteten 16 binäre semantische Merkmale verwendet.
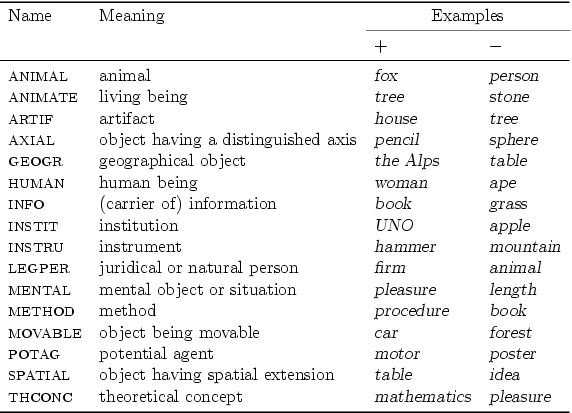
Abbildung 1: Binäre semantische Merkmale
Jedes lexikalische Konzept ist hinsichtlich seiner ontologischen Sorten und seiner semantischen Merkmale klassifiziert, welche zusammen die sogenannte semantische Sorte der Konzepts bestimmen. Die semantische Valenz von Einträgen bzw. Konzepten wird mit Hilfe bestimmter MultiNet-Relationen, den sogenannte kognitiven Rollen (AGT, BENF, etc.), beschrieben. Selektionsrestriktionen können ebenfalls mittels ontologischer Sorten und semantischer Merkmale vorgegeben werden. Die folgenden Angaben skizzieren die semantische Klasse und den Kasusrahmen des Verbs informieren:
action, MENTAL-
| AGT | OBJ | MCONT |
| LEGPER+ | LEGPER+ | |
| NP[nom] | NP[acc] | PP[über, acc] |
| obligatorisch | optional | optional |
Das so beschriebene Verb denotiert eine nichtmentale Handlung mit drei Partizipanten, die entsprechend als Agens (AGT), neutrales Objekt (OBJ) und mentaler Inhalt (MCONT) charakterisiert sind, wobei nur der erste von diesen (im Aktivsatz) syntaktisch realisiert sein muss. Außerdem sind als Agens und neutrales Objekt nur potentielle Agenten (POTAG+) zugelassen. (Es sei darauf hingewiesen, dass das Merkmal MENTAL+ auf rein mentale Prozesse beschränkt ist, wie sie in Verben wie träumen oder denken zum Ausdruck kommen.)
Die Kategorisierung von Lexemen durch semantische Sorten und
Kasusrahmen ist explizit in die im folgenden Abschnitt
erläuterte
Werkmal-Wert-Darstellung der HaGenLex-Einträge integriert.
Zusätzlich steht ein Merkmal NET bereit, um
weitere semantische Angaben in Form beliebiger
MultiNet-Ausdrücke
in Lexikoneinträge aufnehmen zu können.
Beispielsweise bringt der MultiNet-Ausdruck
(GOAL c n1) (MEXP n1 x2) (MCONT n1 x3) (SUBS n1 "wissen.1.1")
als Teil des NET-Wertes des Lexems informieren
zum Ausdruck,
dass wenn x1 x2 über x3 informiert, dann
x1 erreichen will, dass x2 x3 kennt.
(Das Symbol c steht dabei für das Konzept des gegebenen
Eintrags.)
Mit Hilfe dieser Methode lassen sich formale
Bedeutungspostulate
in HaGenLex angeben [2].
Die Einträge von HaGenLex sind in systematischer Weise auf die lexikalischen Einheiten von GermaNet [3] bezogen. Diese Zuordnung, die von den HaGenLex-Lexikographen aufgebaut und gepflegt wird, erlaubt es, die sinnrelationalen Zusammenhänge von GermaNet auf HaGenLex zu projizieren, um beispielsweise die semantische Konsistenz von HaGenLex zu überprüfen oder den Interlingua-Index von EuroWordNet zu nutzen.
Der internen Repräsentation von HaGenLex-Einträgen liegt ein getypter Merkmal-Wert-Formalismus zugrunde, der die Darstellung von Listen und Disjunktionen sowie auch die Angabe von Mengen atomarer Typen unterstützt. Pfad-Identitäten werden von der Implementierung nicht unterstützt, was keine Einschränkung darstellt, da die Merkmalsstrukturen von HaGenLex nur zur Darstellung lexikalischer Information eingesetzt werden, und nicht für phrasale Regularitäten.
Die Typhierarchie von HaGenLex hat die Gestalt eines taxonomischen Baumes - insbesondere sind alle direkten Untertypen eines Typs paarweise inkompatibel. Neben den lexikalischen Standardtypen wie case stellt die Typhierarchie von HaGenLex auch die ontologischen Sorten und lexikalisch relevanten semantische Relationen von MultiNet bereit. Wie in getypten merkmalsbasierten Ansätzen üblich, ist ein Merkmal der HaGenLex-Merkmalsarchitektur nur in Strukturen bestimmten Typs zulässig, wobei die möglichen Werte des Merkmals ebenfalls von dem Typ der Struktur abhängen. Beispielsweise ist das Merkmal MORPH nur in Strukturen des Typs sign zulässig. Da word ein Untertyp von sign ist, und jeder Typ von seinem Obertyp alle dort zugelassenen Merkmale erbt, ist das Merkmal MORPH auch für den Typ word zulässig. Eine (nichtredundante) Liste der zulässigen Merkmale und ihrer entsprechenden Werte für einen gegebenen Typ wird auch als die dem Typ zugeordnete Merkmalsdeklaration bezeichnet. Es folgt eine Beispielliste von fünf (leicht vereinfachten) HaGenLex-Merkmalsdeklarationen:
|
|
||||||||||||||||||
|
|
|
||||||||||||||||||||||||||||||||||||
Da die Merkmalsstrukturdarstellung eines lexikalischen Eintrags den Typ word hat, und word Untertyp von sign ist, sind die Merkmale auf der obersten Ebene einer solchen Struktur durch die Merkmalsdeklarationen von word und sign bestimmt. Der Wert des Merkmals SEMSEL ist eine Struktur vom Typ semsel, dessen oberste Merkmalsebene durch die Deklaration von von semsel festgelegt ist; Merkmalsstrukturen dieses Typs repräsentieren die Semantik und die Valenz eines Lexems. Die Valenzinformation wiederum ist durch eine Liste von Strukturen des Typs select-element kodiert, wobei jedes der Listenelemente einem Komplement entspricht, das durch eine Menge von semantischen Relationen (REL), seine syntaktische Notwendigkeit (OBLIG) sowie seine Beschreibung durch eine Struktur vom Typ sign (SEL) bestimmt ist. Strukturen vom Typ sem schließlich kennzeichnen die Semantik lexikalischer Einträge durch ihre semantische Sorte (ENTITY), zusätzliche MultiNet-Ausdrücke (NET), Schichtenmerkmale (LAY) und Polysemietyp (MOLEC).
Da Merkmalsdeklarationen nur sehr eingeschränkte Möglichkeiten zur Beschreibung lexikalischer Regularitäten bereitstellen, verwendet HaGenLex zusätzlich den sogenannten IBL (Inheritance-Based Lexicon) Formalismus [4], der die Formulierung komplexerer Bedingungen sowie von Defaults durch den Einsatz von Klassen erlaubt. Unter einer Klasse wird dabei ein benanntes Bündel von Attribut-Wert-Bedingungen verstanden, das typischerweise eine unterspezifizierte Merkmalsstruktur beschreibt. Die Klasse verb beispielsweise ist folgendermaßen definiert, wobei Default-Angaben durch Fragezeichen gekennzeichnet sind:
verb [Eine Klasse kann Information von anderen Klassen direkt oder eingebettet über Merkmalspfade erben. Die Klasse verb ist nicht-lexikalisch in dem Sinne, dass sie in verschiedenen lexikalischen oder nicht-lexikalischen Klassen zum Einsatz kommt. Mit einer lexikalische Klasse ist die IBL-Darstellung eines Lexikoneintrags gemeint; als IBL-Klasse erbt sie die Information ihrer Oberklassen. Die IBL-Darstellung des HaGenLex-Eintrags für informieren hat die folgende Gestalt:
word
syn [
v-syn
perf-aux ?haben
sep-prefix ?""
v-type ?main
v-control ?nocontr]]
"informieren.1.1" [Indem man alle Klassen eines Eintrags gemäß ihrer Definition auflöst, erhält man die expandierte Form des Eintrags (Beispiel: expandierter Eintrag zu informieren, dargestellt als Attribut-Wert-Matrix).
verb
semsel [
v-nonment-action
sem net /(goal c n1) (mexp n1 x2) (mcont n1 x3) (subs n1 "wissen.1.1")/
select <
[
agt-select
sel semsel sem entity legper +]
[
ornt-select
oblig -
sel [
syn np-acc-syn
semsel sem entity legper +]]
[
mcont-select
oblig -
sel syn (ueber-acc-pp-syn zu-dat-pp-syn darueber-dass-syn darueber-wh-syn none-wh-syn)] >
compat-r {dur tlim}
example "(Der Minister) (informiert) (das Parlament) (über das Gesetz)."
entail "x1 informiert x2 über x3: x2 hat nach c Kenntnis von x3"]
g-id "1 2"
origin "DS 1997-11-10"
history "FB 2002-11-26: sem net, select, entail"]
Die aktuelle Implementierung von HaGenLex basiert auf der Programmiersprache Scheme. Expandierte Einträge lassen sich zudem automatisch in verschiedene XML-Formate überführen [5].
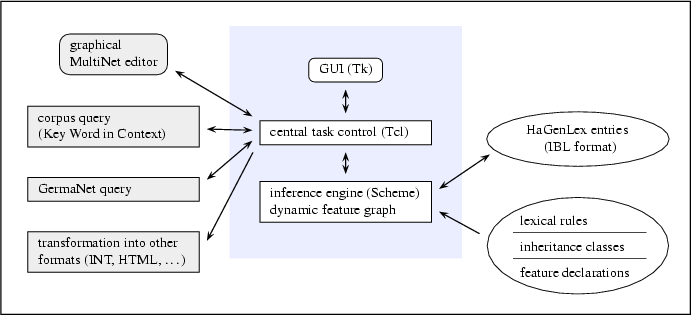
Die Erstellung und Pflege der HaGenLex-Einträge wird durch die Werkbank LIA (Lexicon in Action) unterstützt, die komfortable Möglichkeiten zum Browsen und Editieren bereitstellt. Der Werkbank LIA liegt eine Zwei-Komponenten-Architektur zugrunde (siehe Abbildung 2). Die mittels Tcl/Tk realisierte Front-End-Applikation kontrolliert die graphische Benutzerschnittstelle, verwaltet die Schnittstellen zu den eingebundenen Fremdwerkzeuge und transformiert die interne Repräsentation in ein benutzerfreundliches Format; die in Scheme implementierte Back-End-Applikation realisiert die durch Benutzeraktionen angestoßenen Inferenzen. Der Inferenzmechanismus von LIA basiert auf den Merkmalsdeklarationen und den Klassendefinition von HaGenLex. Außerdem werden LIA-spezifische lexikalische Regeln eingesetzt, um den Editierungsprozess durch Default-Inferenzen zu beschleunigen.
LIA erlaubt dem Benutzer die Erstellung und Modifikation lexikalischer Einträge ohne tiefere Kenntnis über deren interne Repräsentation. Zu diesem Zweck bietet LIA alle Auswahlmöglichkeiten, etwa für den semantischen Typ eines bestimmten Substantivs oder eines nominalen Komplements, mittels leicht verständlicher Paraphrasen dar. Zudem unterstützt LIA Entscheidungen des Lexikographen durch die Abfrage von Akzeptabilitätsurteilen; beispielsweise wird die Information darüber, ob die Komplemente eines Verbs obligatorisch oder optional sind, durch die Darbietung von Beispielsätzen abgefragt, in denen einzelne Komplemente fehlen. Was Browsing betrifft, so erlaubt LIA dem Benutzer, durch freie Selektion von Merkmal-Wert-Kombinationen in flexibler Weise Teilsichten auf das Lexikon zu erzeugen.
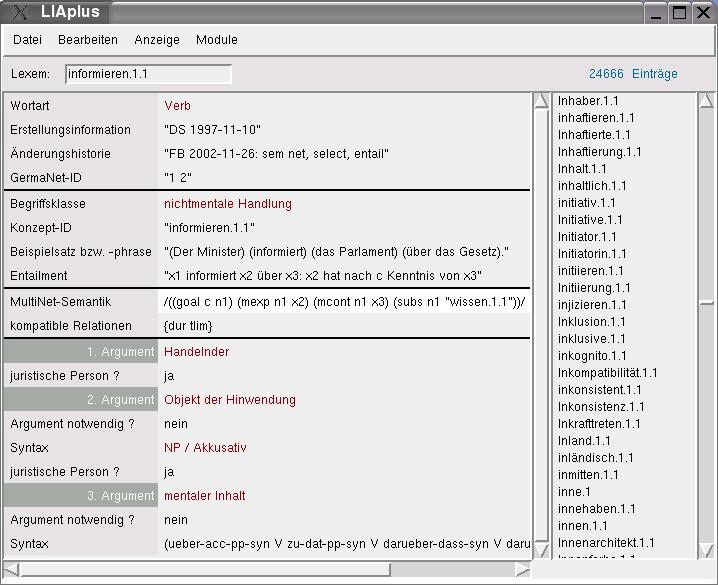
Abbildung 3: Darstellung des HaGenLex-Eintrags für das Verb informieren
durch LIA
LIA stellt verschiedene Schnittstellen zu anderen Software-Komponenten des HaGenLex-MultiNet-Systems zur Verfügung. So können etwa lexikalisch-semantische Spezifikationen in Form von MultiNet-Ausdrücken mit Hilfe eines graphischen MultiNet-Editors bearbeitet werden, den die Werkbank für der Wissensingenieur MWR, bereitstellt (siehe Abbildung 4).
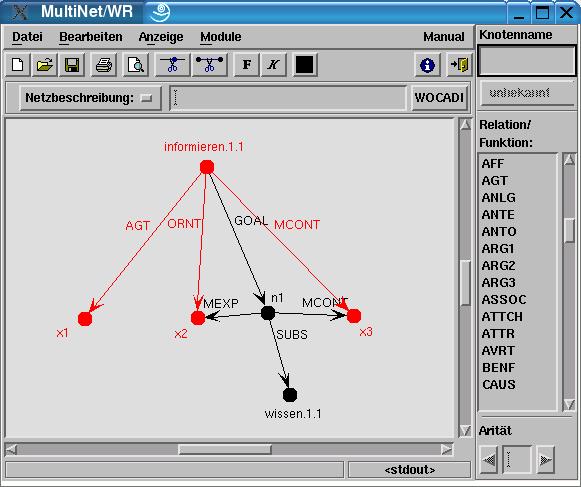
Abbildung 4: MultiNet-Semantik (relationaler Anteil) für den
in Abbildung
3 gezeigten HaGenLex-Eintrag
Diese Schnittstelle kann auch dazu verwendet werden, die MultiNet-Analyse des Beispielsatzes eines Eintrags darzustellen, die ihrerseits mit Hilfe des syntaktisch-semantischen Parsers WOCADI erzeugt wird. Der Lexikograph kann so überprüfen, ob der vorliegende Eintrag bezüglich des Beispielkontextes korrekt semantisch beschrieben ist.