 |
|
 |
|
Bei wachsendem Bedarf nach Informationen wird es mit gleichzeitig steigender Informationsflut immer schwieriger, im World Wide Web (WWW) passende Informationen zu vorgegebenen Fragen zu finden. Es wird immer wichtiger, präzise Antworten auf Fragen zu liefern, statt einem Nutzer Sammlungen von Links oder ganze Web-Seiten zum Weiterlesen anzubieten. Es geht verkürzt gesagt darum, relevante kurze Antworten an Stelle ganzer Web-Seiten zu liefern. Hierzu sind sowohl Methoden des traditionellen Information Retrieval (IR) als auch des Sprachverstehens, d.h. der Künstlichen Intelligenz (KI) und der Computerlinguistik, einzusetzen und miteinander zu verbinden. Das Semantic Web (SW) ist eine Erweiterung des heute existierenden WWW mit dem Ziel, Information eine Bedeutung zu geben, um eine bessere Mensch-Maschine-Kommunikation zu ermöglichen. Die derzeit unter diesem Stichwort untersuchten Methoden sind dennoch nicht ausreichend. Im Semantic Web wird der Inhalt von Informationsressourcen nicht hinreichend genau repräsentiert, um eine präzise logische Fragebeantwortung zu ermöglichen. Es fehlt eine automatische semantische Annotation von Web-Seiten mit vollen Bedeutungsstrukturen, die Voraussetzung für eine erfolgreiche Anwendung der Semantic Web-Technologie ist.
Als wichtige Grundlage zur Lösung dieses Problems wird deshalb die automatische Annotation von Informationsresourcen im WWW mit vollen Bedeutungsstrukturen und die Fragebeantwortung mit Hilfe von logischen Inferenzen betrachtet (so genanntes ESW - Enhanced Semantic Web). Der Einsatz dieser Technologie geht über das einfache Semantic Web hinaus, das im wesentlichen auf einer ontologiegestützten Suche beruht, während das ESW ein volles Sprachverstehen anstrebt. Das ESW stellt gewissermaßen ein Semantic Web der zweiten Generation dar.
Im Projekt sollen Methoden entwickelt werden, die Verfahren aus dem IR mit Ansätzen zum semantischen Retrieval und zur logischen Fragebeantwortung kombinieren. Die semantischen Annotationen von Web-Seiten werden dabei aus einer tiefen Inhaltsanalyse gewonnen und dienen als Basis für intelligente Suchverfahren. Als Ergebnis wird ein Frage-Antwort-System (FAS) auf der Basis einer formalen Wissensrepräsentation entwickelt, in der die neu entwickelten Methoden für die Suche im Web eingesetzt werden (IRSAW -- Intelligent Information Retrieval on the Basis of a Semantically Annotated Web). Nach einer Evaluation dieses FAS wird es zusammen mit einem Dienst zur semantischen Annotation von Web-Seiten als Web-Service bereit gestellt.
Das Projekt dient der Untersuchung und Entwicklung von Verfahren, die Methoden des traditionellen IR mit Verfahren der inferentiellen Fragebeantwortung aus der KI zu einer inhaltsorientierten Suche kombinieren. Insbesondere geht es in dem hier beantragten Projekt darum, die im Bereich Natürlichsprachlicher Interfaces für Internet-Datenbanken (NLI-Z39.50) und im Bereich Frage-Antwort-Systeme (InSicht) entwickelten und erfolgreich eingesetzten Verfahren miteinander zu kombinieren und für ein Erweitertes Semantisches Web nutzbar zu machen.
Ein reiner IR-Ansatz zur Fragebeantwortung (Verfahren A) würde Texte in Segmente unterteilen und eine Kandidatenmenge der Segmente bestimmen, die möglicherweise die Antwort enthalten. Bei der Informationsextraktion werden die Segmente nach einem Relevanzkriterium bzgl. der Frage angeordnet und als Antwort ein Textsegment ausgewählt. Die Herausforderung besteht bei diesem Ansatz in der Bestimmung der Textsegmente zur Fragebeantwortung und in der Bestimmung ihrer Größe bzw. in der Bestimmung der Indexierungsterme.
Ein traditioneller NLP-Ansatz (Verfahren B) besteht in einem reinen Matching (Abgleich) der semantischen Repräsentation von Textabschnitten und der semantischen Repräsentation der Frage. Die Herausforderung hierbei liegt darin, Parsen, Interpretation und Matching von Frage und Dokumenten auf einer großen Dokumentmenge hinreichend effizient für praktische Anwendungen durchzuführen.
Durch die Kombination der Verfahren A und B sind im Hinblick auf Standard-Evaluationsgrößen wie Präzision und Recall deutliche Vorteile gegenüber der Anwendung der einzelnen Verfahren zu erwarten, wobei gleichzeitig die geringere Effizienz von Verfahren B verbessert wird.
Die inhalts- und logikorientierte Suche in der Kombination der Verfahren stützt sich auf eine semantische Annotation von Informationsressourcen. Dafür soll ein Verfahren entwickelt werden, das den Inhalt von Web-Seiten einer tiefen semantischen Analyse unterzieht und eine semantische Repräsentation der Web-Seite in Form von MultiNet-Strukturen erzeugt. Für die Evaluation dieser Annotation muß ein Testumgebung entwickelt werden, mit der die Qualität der Annotation untersucht werden kann.
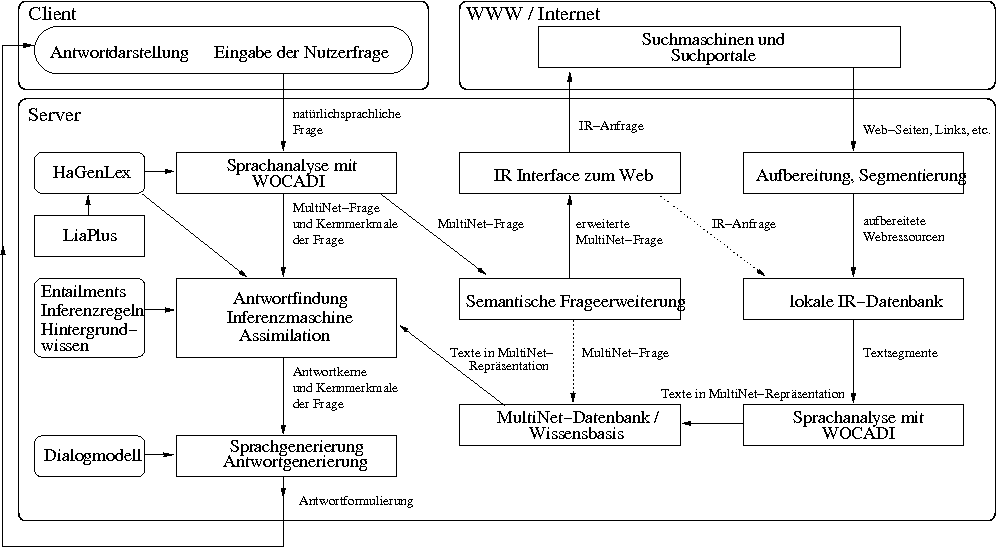 Architektur von IRSAW zur intelligenten
Suche im WWW.
Die Pfeile geben die Richtung des Datenflusses an.
Gestrichelte Pfeile kennzeichnen eine mögliche parallele Verarbeitung.
Architektur von IRSAW zur intelligenten
Suche im WWW.
Die Pfeile geben die Richtung des Datenflusses an.
Gestrichelte Pfeile kennzeichnen eine mögliche parallele Verarbeitung.
Für die Fragebeantwortung sehen wir ein mehrstufiges Verfahren vor. Obige Abbildung zeigt die Gesamtarchitektur des im Projekt zu entwickelnden Informationsrechereche- und Annotationssystems IRSAW. Die Anfrageverarbeitung verläuft wie folgt:
Im Projekt sollen Frage-Antwort-Strategien auf der Basis Mehrschichtiger Erweiterter Semantischer Netze für die Bearbeitung komplexer Nutzerfragen erarbeitet werden, die weit über den aktuellen Stand der Forschung hinausgehen.